Pune diacritice
În limba română scrierea cu diacritice nu este opțională. Literele formate cu semne diacritice au valoare fonetică distinctă (față de literele de la care se formează). Lipsa unui semn diacritic poate schimba sensul cuvântului (ex. tata, țața) generând ambiguități.
Aici este un experiment foarte util: Transformarea unui text în varianta corectă cu diacritice, folosind Inteligența Artificială. Aplicația învață de la cei care o folosesc. Este alcătuită dintr-un modul (algoritm) și un modul de . Soluția s-a născut dintr-o necesitate personală, însă o puteți folosi și voi gratuit.
Problema
Există aplicații pe Internet care pretind că au rezolvat problema transformării în text diacritice. Însă, corectura lor este imprecisă. Ele înlocuiesc cu precizie numai cuvintele pentru care singura formă validă este cea cu diacritice. În cazul cuvintelor unde există ambiguități, acestea sunt înlocuite cu (probabil) varianta cea mai des întâlnită. De asemenea, niciuna nu este capabilă să corecteze cuvintele românești care au semne diacritice greșite (sedile, accente, umlaut-uri etc.). Este evident că toate se bazează doar pe un simplu vocabular predefinit + metoda statistică, fără să cunoască deloc limba română.
Soluția
Abordarea mea este "outside the box". "înțelege" limba română. Analizează textul ținând cont de morfologia, sintaxa și ortografia limbii române. Este o aplicație de Inteligență Artificială care deduce contextul în care apare cuvântul. Își îmbunătățește performanța pe măsură ce este utilizată. Se autoinstruiește, iși îmbogățește vocabularul și își definește singură regulile, numai ca urmare a interacțiunilor cu utilizatorii. Simplu!
De ce așa?
Primul impuls al unui programator, este să automatizeze în modul cel mai direct cu putință. Să afle repede unde se pun semnele diacritice. Pare logic, nu-i așa? Ei bine, nu! E greșit să încerc să determin unde se pun niște semne. Importantă este identificarea cuvântului potrivit contextului. Pentru , casă este un cuvânt de sine stătător, nicidecum nu-i casa cu un semn deasupra. Transformați acest text banal La mine-n casa toarce mata. In casa din lunca e frumoasa mea. In casa de langa, e o alta frumoasa, da' i-a lui Gheorghita. și veți descoperi cum toarce mâța, cum casa și frumoasa sunt potrivite în context, iar vecinul Gheorghita (nume propriu) și-a primit și codița și căciulița.
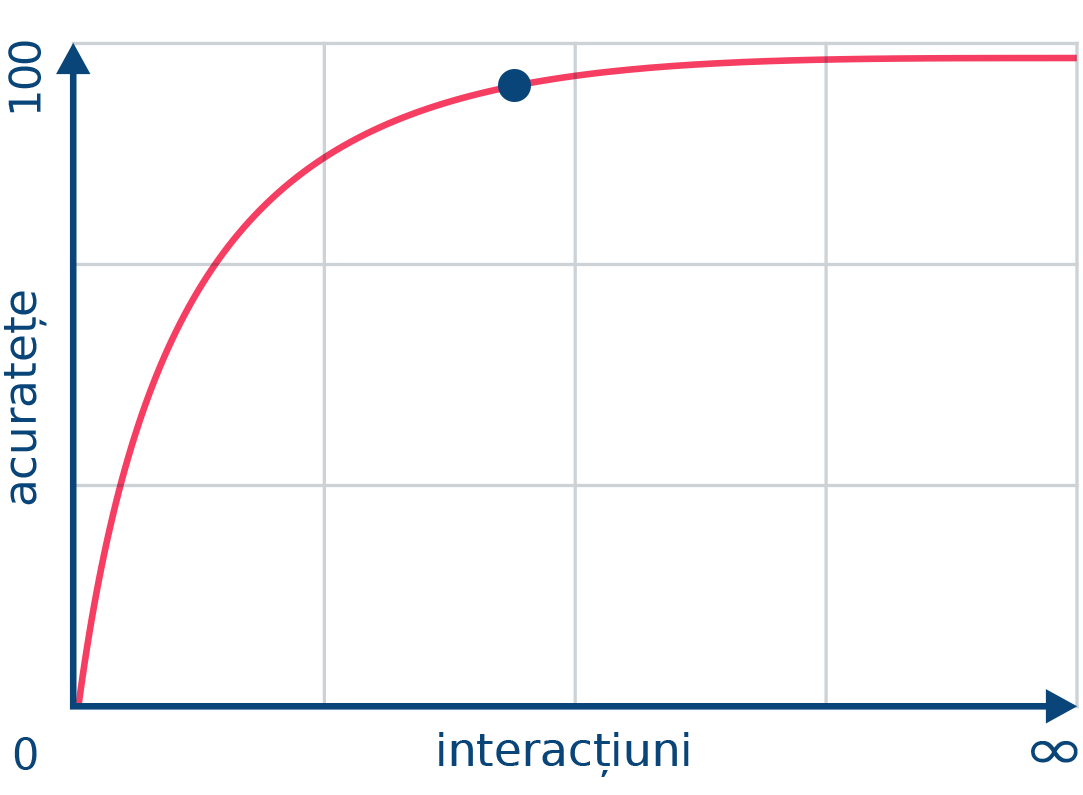
Acuratețea
Este mult tuturor celorlalte aplicații și crește continuu pe măsură ce analizează tot mai multe texte din toate domeniile.
Contribuția ta
La fiecare transformare pe care o faci, în mod indirect, contribui la dezvoltarea aplicației. învață exclusiv din interacțiunea cu utilizatorul. Ori de câte ori faci o corecție sau apeși(evaluare), ajuți aplicația să se dezvolte. De asemenea, primesc bucuros criticile sau observațiile tale pe .